Algo de historia
Desde hace un par de años atrás hemos venido observando el auge de lenguajes de programación distintos a los convencionales de paradigma imperativo (C/C++, Java, C#, PHP, etc.), como por ejemplo Erlang y Scala. La pregunta es por qué?
Para explicar este fenómeno que esta sucediendo y que a medida que pasa el tiempo se hace más fuerte, tenemos que referirnos primero a la historia. Algo sucedió en el año 2002, algo que cambiaría la forma en que se diseñaban y se construían los Microprocesadores. Normalmente los chips venían haciéndose durante los últimos 20 años cada vez más grandes y su frecuencia de reloj cada vez más rápida, hasta que en el 2002 alcanzaron los límites del Hardware: "no se podía abarcar todo en chip en un solo ciclo de reloj". Esto significó una catástrofe para el Hardware, ya que significaba dejar de escalar.

Figura 1: Fracción del Chip alcanzable en un ciclo de reloj [7].
En la Figura 1 podemos observar cómo desde el año 2000 viene en una caída exponencial el porcentaje del chip alcanzado en un ciclo de reloj. Ahora revisemos qué ha pasado durante los últimos 25 años. En la Figura 2, la curva verde nos muestra cómo han venido haciéndose cada vez más grandes los chips, aumentando significativamente el número de transistores. Por otro lado vemos la tendencia logarítmica de la velocidad de reloj (curva azul), la potencia (curva azul claro) y el desempeño por ciclo de reloj (curva morada), se observa claramente cómo han venido atenuándose estas variables. En conclusión, vemos que la escalabilidad vertical de los chips había llegado a su límite, y en la gráfica se puede observar el punto de inflexión en al año 2002.
"... Los circuitos electrónicos están limitados últimamente en cuanto a su velocidad de operación por la velocidad de la luz... y muchos de estos circuitos ya estaban operando en la escala de los nanosegundos"
[Bouknight et al., The Illiac IV System. 1972] [1].

Figura 2: Tendencias en las CPU de Intel (2009).
"... Por primera vez en la historia nadie está construyendo procesadores secuenciales más rápidos. Si quieres que tus programas corran significativamente más rápido, por ejemplo, para justificar la adición de nuevas características, vas a tener que paralelizar tus programas"
[Ref. 1. Patterson y Hennessy].
Desde el año 2005 no se producen Microprocesadores secuenciales más rápidos. El paradigma de las arquitecturas de cómputo se ha volcado completamente a las arquitecturas de múltiples CPU, arquitecturas Multicore y/o Multiprocesadores. La Figura 3 y la Figura 4 son algunos ejemplos de los tipos de arquitecturas de Hardware que vemos hoy en día.

Figura 3: Arquitectura Tile64 [8].

Figura 4: PlayStation3 Cell Processors, Multi GPUs Architectures.
Ahora bien, y eso qué tiene que ver con los lenguajes de programación? Sencillamente que cuando las arquitecturas de cómputo cambian, los lenguajes de programación también lo hacen, ya que están estrechamente relacionados. Los lenguajes de programación no habían cambiado durante los últimos 25 años, porque las arquitecturas de Hardware no habían cambiado durante los últimos 25 años, pero ya lo hicieron. Hace 25 años no había presión de cambiar los lenguajes de programación, pero cuando el Hardware empieza a cambiar, los lenguajes de programación empiezan a cambiar también.
Cuánto duele? Seguramente desperdiciar 2 cores no duele, 4 cores dolerá pero muy poco, 8 cores duele un poco más, 16 cores ya empieza a doler, 32 cores ya duele bastante (Intel "Keifer" project: 32 cores 2009/2012 [9]), 1M cores "ouch" (2019, complete paradigm shift) [4] [6]. El paradigma del Hardware se ha volcado a la concurrencia y/o paralelismo, por lo tanto, el Software debe hacerlo también. Surge entonces un nuevo paradigma llamado "Concurrency-Oriented Programming" [Ref. 4. Joe Armstrong].
Estado Mutable y Concurrencia
Por qué lenguajes de programación como Java, C, C++, C#, etc., no encajan bien en estas nuevas arquitecturas de cómputo? Bueno esto se debe a varios factores, pero vamos a empezar hablando de dos que podrían ser los más relevantes: estado mutable y concurrencia.
"Pero cómo podríamos hacer para que nuestros programas corran más rápido en una CPU multicore? Todo gira en torno al estado mutable y a la concurrencia"
[Ref 4. Joe Armstrong].
Para empezar, mencionemos los modelos de concurrencia conocidos en la actualidad:
- Traditional Multithreading
- Hilos de SO
- Memoria compartida, bloqueos, etc.
- Async or Evented I/O
- I/O loop + callbacks
- Memoria compartida, futures (invocación asíncrona de métodos)
- Actor Model
- Los "procesos" no comparten nada
- Mensajería soportada de forma nativa
Por ejemplo, Erlang, Oz, Occam y más recientemente Scala, optaron por "Paso de Mensajes" (Actor Model [5]), todos los demás como: Java, C, C++, C#, Ruby, Python, PHP, Perl, etc., se fueron por el modelo de "Memoria Compartida" (Traditional Multithreading and/or Async I/O).
En el modelo de paso de mensajes no existe estado compartido. Todos los cómputos son realizados dentro del proceso, y la única forma de intercambiar datos es través de paso de mensajes asíncrono. Pero por qué es bueno esto?
La concurrencia a través de memoria compartida involucra la idea de "estado mutable" (literalmente memoria que puede ser modificada). Lenguajes como Java, C, C++, C#, Python, Ruby, PHP, etc., tienen la noción de que hay algo llamado "estado" y que podemos cambiarlo. Esto esta bien en la medida de que solo se tenga un proceso realizando el cambio. Si lo que se tienen son múltiples procesos compartiendo y modificando la misma memoria, lo que se tiene es la receta para el desastre [4].
Normalmente para evitar modificaciones simultaneas sobre la memoria compartida usamos mecanismos de bloqueo, también conocidos como Mutex, métodos sincronizados, etc., pero al final de cuentas, bloqueos.
Escenario 1: Si algún programa falla en la sección crítica (cuando obtiene el candado o bloqueo), resulta un desastre. Los otros programas no saben qué hacer, no se dan cuenta qué pasó y por lo tanto no hay forma de que se puedan recuperar –podrían quedarse esperando indefinidamente por el candado, ya que como el programa que lo adquirió primero murió, no habrá nadie quien lo libere. Escenario 2: Si algún programa corrompe la memoria en el estado compartido, un desastre ocurre también. Al igual que en el anterior escenario, los otros programas no saben que hacer, no se dan cuenta qué pasó y por lo tanto no hay forma de que se puedan recuperar tampoco. Ahora bien, cómo hacen los programadores para solucionar este tipo de problemas? Con gran dificultad seguramente. Memoria compartida es el camino difícil. La tolerancia a fallos es difícil de lograr con memoria compartida –compartir es la propiedad que previene la tolerancia a fallos.
Programar sobre arquitecturas multicore es difícil a razón del estado compartido y mutable. Los lenguajes de programación funcionales no tienen estado compartido y tampoco estado mutable. Lenguajes como Erlang y Scala tienen las propiedades intrínsecas adecuadas para programar sobre ordenadores de múltiples núcleos –la concurrencia se mapea en las múltiples CPUs, no mutabilidad significa que no tenemos problemas de corrupción de memoria.
Pieter Hintjens, CEO de iMatix (compañía creadora de ZeroMQ) plantea la siguiente ley para la concurrencia:
Hintjens’ Law of Concurrency
E = MC2
E is effort, the pain that it takesM is mass, the size of the codeC is conflict, when C threads collide
La E representa el esfuerzo, el costo que toma logar desarrollar aplicaciones concurrentes. La M es la masa o el tamaño de código. Por último, la C representa el conflicto, cuando un número C de hilos colisionan. Esto quiere decir que entre más hilos tengamos compartiendo memoria, el esfuerzo para lograr la concurrencia incremente exponencialmente (en potencia de 2), lo cual por supuesto degradara el desempeño de igual forma. Ver Figura 5.

Figura 5: Ley de concurrencia de Hintjens: E = MC2 [12].
Ahora, con ZeroMQ la ecuación funciona pero C es constante: E = MC2, para C = 1 (Figura 6). ZeroMQ es un conjunto de herramientas (librería) para la comunicación a través de paso de mensajes, hechas para la concurrencia y sistemas distribuidos. ZeroMQ proporciona bindings para distintos lenguajes como C, C++, Java, Python, Ruby, PHP, Scala, Erlang, etc., lo cual facilita la construcción de aplicaciones concurrentes, orientadas al paso de mensajes, en casi cualquier plataforma y/o lenguaje de programación, es otra alternativa que definitivamente vale la pena explorar.

Figura 6: Ley de concurrencia de Hintjens: E = MC2, para C = 1 [12].
Erlang de forma nativa (implementa de forma nativa el modelo de actores) y Scala con Akka (el modelo de actores es opcional en Scala), siguen el mismo comportamiento de la Figura 6, E = MC2 para C = 1 –debido a que ambos hacen uso de paso de mensajes y trabajan bajo la premisa de "no se comparte nada".
Impedance Mismatch
"... El mundo es concurrente pero programamos en lenguajes secuenciales"
[Ref. 4. Joe Armstrong].
Hay una impedancia al tratar de programar aplicaciones paralelas y/o concurrentes con lenguajes de programación secuenciales (paradigma imperativo), ya que estos lenguajes discrepan o no hacen match de forma natural con los paradigmas orientados al paralelismo y/o concurrencia –no encajan naturalmente en las arquitecturas multicore o multiprocesador. Es artificialmente complejo construir programas con alto grado de paralelismo y/o concurrencia, distribuidos, tolerantes a fallos, etc., con lenguajes de programación secuenciales –añaden una complejidad artificial [4][6].
Los lenguajes de programación secuencial, de paradigma imperativo, no modelan la realidad, arquitecturas multiprocesador y/o multicore. Muchos de ellos fueron concebidos hace más 15 años, cuando todavía la tendencia en la Microelectrónica era construir procesadores más grandes y rápidos, efectivos para ejecutar lógica secuencial. Pero como lo he venido repitiendo, ya el enfoque cambió, y radicalmente, por lo tanto, los lenguajes de programación deben hacerlo también –están directamente relacionados con las arquitecturas de cómputo.
Algunos Ejemplos
Veamos con ejemplos a que se refiere la complejidad artificial y/o accidental.
"... Programar consiste en sobrellevar dos cosas: las dificultades accidentales, cosas las cuales son difíciles porque se estén utilizando herramientas de programación inadecuadas, y cosas que son realmente difíciles, las cuales ninguna herramienta de programación o lenguaje va a resolver."
Joel Spolsky reviewing Beyond Java
Ejercicio 1: Seguramente han escuchado hablar del problema: "El anillo mortal de procesos (o hilos)". Consiste en que el programa crea un hilo, cuya lógica es crear un hilo hijo, enviarle un mensaje para que muera y quedarse esperando el mensaje correspondiente de su padre para morir. Cuando se llegue a un número N de hilos creados, valor que se ingresa como parámetro, el programa deja de levantar más hilos y espera a que todos los hilos creados hayan concluido. El la Figura 7 podemos visualizar la estrategia para resolver el ejercicio. Se observa que los hilos se van creando progresivamente y van muriendo de la misma manera. La idea no es levantar N hilos y luego si que se eliminen, debe ser una tarea progresiva. Ahora viene el reto, resuelvan el problema en Java, C, C++, C#, Python, Ruby, PHP, etc., cualquier lenguaje de paradigma imperativo (secuencial).
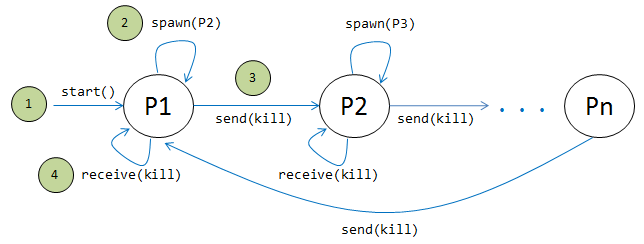
Figura 7: Anillo mortal de procesos/hilos.
El programa en sí, no hace uso al 100% de las arquitecturas multicore, debido a que a pesar que se creen miles o millones de hilos, solo van a haber pocos de ellos ejecutándose en un instante determinado de tiempo –lo que si vamos a poder ver es el overhead que existe al crear y eliminar hilos, dependiendo del lenguaje de programación escogido para desarrollar el problema. Sin embargo, para el propósito sirve, porque la idea es mostrar la complejidad que existe al construir un programa sencillo como este –que involucra hilos/procesos y comunicación entre ellos– en un lenguaje de programación de paradigma imperativo (Java, C, C++, C#, etc.).
El programa involucra manejo de hilos y comunicación entre ellos. Para la comunicación podemos usar memoria compartida o paso de mensajes. Si usamos memoria compartida tendremos que usar mecanismos de sincronización (bloqueos). En un lenguaje como Java, C#, C o C++, si queremos usar paso de mensajes, seguramente nos toca lidiar con sockets, pipes u otros mecanismos de IPC (Inter Process Communication). En cualquiera de los casos, con un lenguaje de paradigma imperativo resulta bastante tedioso y complicado resolver el problema. Ahora veamos en la Figura 8 la solución en un lenguaje orientado a la concurrencia (Concurrency-Oriented Programming [Ref. 4. Joe Armstrong]), como Erlang:

Figura 8: Solución del anillo mortal de hilos en Erlang.
En la Figura 9 se puede observar la ejecución del programa, inicialmente con 100.000 procesos, luego con 1.000.000 y por último con 10.000.000. Se usó una función de Erlang (timer:tc) para calcular el tiempo que toma el programa en ejecutarse, como respuesta arroja una tupla de 2 elementos ({Time, Value}), el primero es el tiempo en microsegundos y el segundo es un valor devuelto por la ejecución (en este caso "ok").

Figura 9: Ejecución del programa de la Figura 8.
En Erlang tan solo necesitamos 10 líneas de código para resolver el problema. El propósito aquí es señalar que hay una gran familia de abstracciones que fácilmente se pueden construir a partir de las primitivas básicas del lenguaje: spawn, send (!) y receive. Estas primitivas se pueden utilizar para crear nuestras propias abstracciones de control paralelo con el fin de aumentar la concurrencia de los programas. No voy a entrar a discutir y/o explicar con detalle el código del programa, ya que no es el propósito de la lectura entender las reglas léxicas, sintácticas y semánticas del lenguaje Erlang, eso lo dejamos para una siguiente ocasión.
Con este ejemplo se ve claramente lo sencillo y natural que es construir un programa orientado a la concurrencia con un lenguaje como Erlang, cuyo modelo de concurrencia sigue el modelo de actores [5], la mensajería esta incorporada de forma nativa en el lenguaje al igual que las funciones para manejo de de concurrencia de forma local y distribuida.
"... Para mi, Erlang/OTP es la clase de sistema que mis colegas de middleware y yo, gastamos años tratando de construir. Tiene tantas cosas que un desarrollador de sistemas distribuidos desea: fácil acceso a redes, bibliotecas y utilidades para que la interacción con nodos distribuidos sea sencilla, un maravilloso soporte a la concurrencia, todas las capacidades de actualización y confiabilidad, y el lenguaje Erlang en sí, es una especie de "DSL para sistemas distribuidos" donde su elegancia y pequeño tamaño lo hacen fácil de aprender y fácil de usar, para que rápidamente se convierta productivo en la construcción de aplicaciones distribuidas."
[Ref. 10. Steve Vinoski].
Ejercicio 2: Vamos a implementar algo que podría parecer un poco más complicado. En muchos lenguajes de programación existe la función de orden superior "map", cuya funcionalidad consiste en aplicar una función dada sobre cada elemento de una lista –la función tiene como entrada una lista de elementos y una función que es la que se aplicará sobre cada elemento de la lista. Bueno, ahora implementemos una versión paralela, una función llamada "pmap" que reciba los mismos parámetros de la versión "map", una lista de elementos (cualquier tipo de elemento) y una función para que sea ejecutada sobre cada elemento de la lista. Luego, "pmap" deberá partir el trabajo, creando un hilo/proceso por cada elemento de la lista para que ejecuten la función sobre el elemento. Luego, la función "pmap" se debe quedar esperando (gather) a tener los resultados de cada uno de los hilos que creó. Cada hilo/proceso envía el resultado a través de un mensaje al proceso que lo creó (en este caso "pmap"). En la Figura 10 se muestra cómo funciona "pmap", y en la Figura 11 está la solución en Erlang.

Figura 10: Versión paralela de la función de orden superior "map" ("pmap").

Figura 11: Solución simple de "pmap" en Erlang.
Podríamos complicar el ejercicio aún más. Otra versión de "pmap" podría no solo distribuir el trabajo en procesos locales sobre una CPU multicore, sino también sobre múltiples nodos en una red distribuida. En este caso, la nueva versión de "pmap", la función "pmap_dist" partiría los jobs usando alguna heurística y distribuiría los pedazos (porciones más pequeñas de jobs) en workers (procesos) corriendo sobre múltiples nodos en una red (incluyendo el local, desde donde se ejecuta inicialmente "pmap_dist"). Luego espera a juntar todos los pedazos procesados para armar el resultado final –los workers envían sus resultados el proceso desde el cual fueron invocados. Ver Figura 12.

Figura 12: Versión distribuida de "pmap" (pmap_dist).
Esta vez no voy a mostrar cómo implementar esta versión distribuida, solo diré que en Erlang es cuestión de añadir un par de líneas más al código, queda como un reto –y más aún en un lenguaje como Java, C, C++, C#, etc.–, inténtenlo!
Modelos Multihilos
Ahora vamos a hacer un análisis a un nivel mucho más bajo, vamos a ir a nivel de Hardware y SO (Sistema Operativo). Por qué? Bueno, el desempeño y escalabilidad del Software sobre las arquitecturas multicore y/o multiprocesador depende de la implementación de procesos e hilos del SO y del modelo multihilos que adopte el lenguaje de programación sobre el SO anfitrión. Pero bueno, vamos a ver con un poco más de detalle de que se trata todo esto.
El soporte para hilos podría ser proveído a nivel de usuario, para hilos de usuario, o a nivel de kernel, para hilos de kernel. Los hilos de usuario son soportados arriba del kernel y son manejados sin soporte alguno del kernel, mientras que los hilos de kernel son soportados y manejados directamente por el SO. La mayoría de Sistemas Operativos contemporáneos –Windows, Linux, Mac OS X, Solaris y Tru64 UNIX– soportan hilos de kernel. Ahora bien, debe existir una relación entre los hilos de usuario y los hilos de kernel [2]. Vamos a repasar rápidamente las tres formas más comunes de establecer dicha relación.

Figura 13. a) Modelo de muchos a uno. b) Modelo de uno a uno. c) Modelo de muchos a muchos. d) Modelo de dos niveles. [Ref. 2. Silberschatz, Galvin and Gagne].
La primera relación "Muchos a Uno" (Figura 13.a) mapea múltiples hilos de usuario a uno de kernel. La administración del hilo es hecha por la librería de hilos en espacio de usuario, de esta forma es eficiente, pero el proceso entero se bloqueará si un hilo hace un llamado bloqueante al sistema. Además, debido a que solo un hilo al tiempo puede tener acceso al kernel, múltiples hilos son incapaces de correr en paralelo sobre multiprocesadores y/o multicores [2]. Este enfoque es usado por muchas máquinas virtuales, donde estos hilos se conocen como "green threads", hilos que son planificados por la máquina virtual en vez de nativamente por el SO, hilos administrados en espacio de usuario. Algunos ejemplos: Java 1.1, Ruby antes de la versión 1.9, CPython con Greenlets, Go, Haskell, Smalltalk, etc. [11].
El modelo "Uno a Uno" (Figura 13.b) mapea cada hilo de usuario a un hilo de kernel. Este modelo provee mayor concurrencia que el modelo de "Muchos a Uno", debido a que permite que otro hilo corra cuando un hilo hace un llamado bloqueante al sistema –esto permite que múltiple hilos corran en paralelo sobre arquitecturas multiprocesador y/o multicore. El único inconveniente con este modelo es que crear un hilo de usuario requiere crear el correspondiente hilo de kernel. Debido a que la sobrecarga de crear hilos de kernel puede afectar considerablemente el desempeño de una aplicación, la mayoría de las implementaciones de este modelo restringen el número de hilos soportados por el sistema. Linux, junto con la familia de sistemas operativos Windows, implementan este modelo de "Uno a Uno" [2].
El último modelo de "Muchos a Muchos" (Figura 13.c) multiplexa varios hilos a nivel de usuario a una cantidad más pequeña o igual de hilos a nivel de kernel. El número de de hilos de kernel puede ser específico para una aplicación en particular o para una máquina en particular (una aplicación podría asignar más hilos de kernel en un multiprocesador que en un solo procesador). Mientras que el modelo de "Muchos a Uno" le permite al desarrollador crear tantos hilos de usuario como él desee, no se obtiene una verdadera concurrencia porque el kernel solo puede planificar un solo hilo de kernel al tiempo. El modelo "Uno a Uno" permite una mayor concurrencia, pero el desarrollador tiene que tener cuidado de no crear demasiados hilos dentro de una aplicación (y en algunos casos puede estar limitado en el número de hilos que puede crear). El modelo "Muchos a Muchos" no sufre ninguno de estos problemas: los desarrolladores pueden crear tantos hilos de usuario como sea necesario, y los correspondientes hilos de kernel pueden ejecutarse en paralelo sobre un multiprocesador y/o multicore. Además, cuando un hilo realiza una llamada bloqueante al sistema, el kernel puede planificar otro hilo para la ejecución [2].
Existe una variación muy popular al modelo de "Muchos a Muchos", aún multiplexa varios hilos de usuario sobre una cantidad más pequeña o igual de hilos de kernel, pero además permite que un hilo se usuario sea asignado a un hilo de kernel. Esta variación algunas veces es referida como "Modelo de Dos Niveles" (Figura 13.d), y es soportada por sistemas operativos como HP-UX, Tru64 UNIX y algunas versiones de Solaris [2].
El SO brinda una librería de hilos, la cual le proporciona al programador un API para crear y administrar hilos. Hay dos formas principalmente de implementar una librería multihilos. El primer enfoque es proveer una librería enteramente en espacio de usuario, sin ningún tipo de soporte de kernel. Todo el código y estructuras de datos existen en espacio de usuario. Esto significa que invocar una función en la librería resulta en un llamado a una función local en espacio de usuario y no en un llamado de sistema. El segundo enfoque es implementar una librería a nivel de kernel soportada directamente por el SO. En este caso el código y estructuras de datos existen en espacio de kernel. Invocar una función en el API de la librería, normalmente resulta en un llamado de sistema al kernel [2].
Las principales tres librerías de hilos usadas hoy en día son: (1) POSIX Pthreads, (2) Win32 y (3) Java. Pthreads, la extensión de hilos del estándar POSIX, podría ser proveída ya sea como una librería a nivel de usuario o a nivel de kernel (en Linux por ejemplo, es a nivel de kernel). La librería de hilos Win32 es una librería a nivel del kernel disponible en los sistemas Windows. El API de hilos de Java, permiten que los hilos sean creados y administrados directamente desde los programas Java. Sin embargo, debido a que en la mayoría de los casos la JVM se está ejecutando en la parte superior del SO anfitrión, el API de hilos de Java es generalmente implementado usando la librería de hilos proporcionada por el SO anfitrión [2].
De igual forma que Java, en otros lenguajes como C#, versiones recientes de Ruby, Python, etc., la implementación de hilos se hace a través de la librería del SO anfitrión, y es aquí donde está el trasfondo del asunto. En el caso de Windows y Linux que prácticamente son los sistemas operativos más comunes y usados, el modelo de hilos es de "Uno a Uno", y las librerías Win32 y Pthreads implementan hilos en espacio de kernel. El problema es que el número de hilos de kernel es limitado, solo podríamos escalar a unos cuantos miles –claramente esto también depende del número de procesadores y/o cores con que se cuente. Que pasa en las aplicaciones o sistemas de concurrencia masiva, bajo este modelo podremos escalar a millones de hilos? Quizás, seguramente venga un proveedor y nos diga que para escalar a ese nivel necesitamos cientos de procesadores y/o cores, en otras palabras, solucionar las falencias del Software con Hardware, algo bastante común hoy en día. Aveces es solo cuestión de optimizar al máximo la utilización de los recursos, de esta forma, con el mismo Hardware podríamos escalar a los niveles de concurrencia deseados. Muchas veces se desperdician demasiados recursos, ya que en la mayoría de los casos se crean hilos de kernel para ejecutar tareas triviales.
Imaginemos que tenemos un típico sistema multicapas (Figura 14). Un usuario que interactúa con el browser, el browser que habla con el servidor y el servidor que habla con la base de datos. Vamos a concentrarnos en el servidor, pero la problemática sucede de igual o de forma similar en la capa o segmento de base de datos. En el servidor tenemos el modelo clásico para manejo de sesiones, cada sesión es representada a través de un hilo, y las tareas de este hilo en la mayoría de los casos es ir a leer o escribir en la base de datos. Si a cada sesión le asignamos un hilo de kernel, estamos limitados en el número de sesiones concurrentes, dependiendo del SO y número de procesadores y/o cores que dispongamos. Si el tráfico sobre nuestro sitio web es considerablemente alto, al punto de requerir más sesiones concurrentes que el disponible de hilos de kernel de la máquina(s), tenemos un problema. Solución inmediata y facilista (llamemos a esta solución "solución tipo proveedor"): "necesitamos más máquinas". Les suena familiar?

Figura 14: Sistema típico multicapas.
Pero que pasa si un hilo de kernel puede manejar tranquilamente el traficó y la carga generada por N sesiones concurrentes? Seguramente optimizaríamos en gran porcentaje la utilización de nuestros recursos, y podríamos decirle al proveedor en la mayoría de los casos que no necesitamos tantas máquinas y/o procesadores como el piensa, ya que con este enfoque necesitamos menos recursos de Hardware para realizar la misma tarea, solamente es cuestión de afinar nuestro Software de tal forma que aproveche al máximo nuestro Hardware. Esto resultara una tarea fácil o extremadamente difícil dependiendo de las herramientas, plataformas y lenguajes de programación que se escojan para construir el sistema.
Voy a hacer un paréntesis aquí. Noten que si contáramos con un SO que implemente un modelo de hilos de "Muchos a Muchos", no habría problema, ya que se puede afinar el SO con un número limitado de hilos de kernel, proporcional al número de procesadores y/o cores, y nuestra aplicación web podría asignar hilos de usuario por sesión (o Green Threads), de tal forma que podamos tener una cantidad mucho mayor de hilos de usuario (sesiones) que de hilos de kernel, por ende, aumentamos la capacidad de atender más sesiones concurrentes sin aumentar infraestructura o recursos de Hardware. La cuestión es que este modelo es soportado por pocos sistemas operativos, y de esos pocos la mayoría de ellos son licenciados, lo cual representa un gran problema si hablamos de cientos, miles o incluso millones de procesadores y/o cores, ya que por lo general el costo del licenciamiento es proporcional al número de ellos. Además, los sistemas operativos más usados en entornos empresariales son Linux y Windows, y el modelo de hilos en estos es de "Uno a Uno".
Lo que necesitaríamos es una plataforma encima del SO, que abstraiga la implementación de procesos e hilos de este, de tal forma que el escalamiento sobre las arquitecturas multicore y/o multiprocesador sea agnóstico al SO. El ejemplo más notable de esto es la implementación de la máquina virtual de Erlang, la cual internamente tiene una especie de SO huésped que implementa un modelo de hilos y/o procesos de "muchos a Muchos". El SO huésped de la ErlangVM cuando inicia, levanta un "Scheduler" (planificador) por cada core que se disponga, y este se ejecuta sobre un hilo de kernel –esto es lo que se conoce como "SMP Schedulers" (Symmetric Multiprocessing Schedulers). Cada planificador tiene asignada una cola de ejecución (Run Queue) a la cual se le asignan un determinado número de procesos. Cuando se crea un proceso en Erlang a través de la función spawn, se crea un LWP (Light-weight process), que son "Green Threads" de Erlang, y este es asignado a una cola de ejecución. Los procesos son distribuidos uniformemente sobre los distintos planificadores, por lo tanto, implícitamente se están distribuyendo sobre los cores, ya que hay N planificadores por cada N cores, cada planificador corre en un hilo de kernel, y los hilos de kernel son administrados por el SO anfitrión y este a su vez los distribuye uniformemente sobre los cores. En la Figura 15 se puede observar una vista de la arquitectura del modelo de procesos de la ErlangVM.

Figura 15: Modelo de procesos de la máquina virtual de Erlang.
Al examinar distintos lenguajes de programación y sus implementaciones, se puede observar claramente por qué Erlang es diferente, es mucho más que un lenguaje de programación, es toda una plataforma (Erlang/OTP) para el desarrollo de aplicaciones distribuidas, tolerantes a fallos, altamente concurrentes y disponibles, etc.
Es importante entonces tener en cuenta que no solo es el lenguaje, que sea de paradigma funcional, orientado a objetos, imperativo, declarativo, etc., sino también en el caso de los lenguajes interpretados (dependientes de una máquina virtual), la implementación de la máquina virtual y/o SO huésped, ya que de aquí depende la escalabilidad y los niveles de la misma sobre las arquitecturas multicore y/o multiprocesador.
Conclusiones
Como primera conclusión tenemos que, a razón de que las arquitecturas de cómputo empezaron a cambiar desde el año 2002, los lenguajes de programación deben hacerlo también, ya que están directamente relacionados. Necesitamos lenguajes que encajen con la realidad de las arquitecturas multicore y/o multiprocesador, que permitan desarrollar aplicaciones concurrentes fácilmente, que permitan escalar a niveles de concurrencia que aprovechen el Hardware al 100%. Los casos más relevantes que encaran esta evolución y revolución de las arquitecturas multicore y/o multiprocesador, son Erlang/OTP, Scala/Akka y ZeroMQ –este último con esfuerzo adicional, ya que es tan solo una librería para paso de mensajes y concurrencia, no un lenguaje y/o plataforma como si lo son los dos primeros.
Por otra parte, para lograr que el Software encaje naturalmente en estas arquitecturas multicore y/o multiprocesador, necesitamos ciertas características en nuestro Software. La primera de ellas y la más importante es el "estado mutable y concurrencia". La idea es evitar el estado compartido y/o mutable, ya que esto hace difícil desarrollar sobre arquitecturas multicore y/o multiprocesador, orientadas al paralelismo (Thread Level Parallelism [1]), es la propiedad que evita escalar y la tolerancia a fallos. Para la comunicación hacer uso de paso de mensajes, no compartir nada (tener como referencia el modelo de actores [5]). Segundo, el modelo de procesos e hilos, este hace referencia a la forma como se crean y administran los hilos y/o procesos dentro del SO anfitrión y el SO huésped. De la forma como el SO anfitrión implemente su modelo multihilos, y la forma en que el SO huésped implemente el suyo, depende la escalabilidad y el nivel de la misma sobre las arquitecturas multicore y/o multiprocesador. Ahora, el SO huésped puede implementar su modelo multihilos ya sea usando directamente la librería de hilos proveída del SO anfitrión (JVM, Ruby, Python, etc.), o creando una capa que abstraiga el modelo multihilos del SO anfitrión y habilite un API para el manejo de hilos a nivel de usuario o "Green Threads" (Erlang). Por último, podríamos mencionar "Impedance Mismatch", lo cual hace referencia a la incompatibilidad de modelos: lenguajes de programación secuenciales vs arquitecturas multicore y/o multiprocesador orientadas al paralelismo. Esta propiedad es lo que causa la complejidad accidental, que hace referencia a cosas que con difíciles o complejas debido a la utilización de herramientas o lenguajes inadecuados, en este caso, la programación de aplicaciones concurrentes, distribuidas y tolerantes a fallos, es extremadamente difícil debido a que lenguajes como Java, C#, C, C++, Ruby, etc., son inadecuados para programar aplicaciones con estas propiedades, se requiere mucho esfuerzo para poder logar alcanzar estas propiedades, y muchas veces no se logran alcanzar a los niveles esperados.
Como reflexión final, me gustaría hacer énfasis en que la forma en la que hemos venido desarrollando aplicaciones esta cambiando, y drásticamente, por lo tanto, es importante empezar a estudiar las arquitecturas de cómputo multicore y/o multiprocesador, junto con lenguajes, plataformas, herramientas, etc., las cuales permitan hacer un uso adecuado de ellas. El paradigma ha cambiado de programar lógica secuencial a programar lógica paralela, hoy hablamos de un paradigma totalmente opuesto orientado a la concurrencia [4].
Referencias
[1] Computer Architecture, A Quantitative Approach – 4th Edition. David Patterson and John Hennessy.
[2] Operating System Concepts – 8th Edition. Abraham Silberschatz, Peter Baer Galvin and Greg Gagne.
[3] Distributed Systems, Principles and Paradigms – 2nd Edition. Andrew S.Tanenbaum and Maarten Van Steen.
[4] Programming Erlang, Software for a Concurrent World – 2007. Joe Armstrong.
[5] Actor Model of Computation: Scalable Robust Information Systems. Carl Hewitt. 2012.
No hay comentarios.:
Publicar un comentario